Before diving into the process, which you have already seen in Figure 2.30, first you need a definition of transformation. A few examples of transformation that you have experienced so far were in Exercise 4.7 and Exercise 4.8. In Exercise 4.7 you changed the structure of brain wave readings from CSV into Parquet format. In Exercise 4.8 you converted a DateTime data type value from epoch to a more human readable format. Other types of transformation, covered later, have to do with cleansing, splitting, shredding, encoding, decoding, normalizing, and denormalizing data. Any activity you perform on the data in your data lake or any other datastore that results in a change is considered a transformation. Transformations may be big, small, low impact, or high impact. In some scenarios, you might receive data that is already in great form and requires minimal to no transformations. In that case, all you need to do is validate it and move it to the next DLZ. In other cases, the data you process may contain unexpected or partial data types, or be corrupted, which often requires manual interventions, like requesting a new file, manually modifying the file or data column, and retriggering the pipeline.
From a transformation process perspective, it is important to cover the different stages of the Big Data pipeline. There are many descriptions of what constitutes the different stages of the Big Data pipeline. Terms like produce, capture, acquire, ingest, store, process, prepare, manipulate, train, model, analyze, explore, extract, serve, visualize, present, report, use, and monetize are all valid for describing different Big Data stages. There are three important points to consider when choosing the terminology for describing your process. The first point is to describe what your definition of each stage means in totality. It must be described to the point where others understand what your intention is and what the inputs, actions, and results of the stage comprise. For example, serve, visualize, and report are very similar and, in many cases, can be used interchangeably. However, you could also consider them totally different stages based on your definition. You have great freedom in defining this process, so long as you abide by the second point.
The second point is that some of the stages need to flow in a certain order. For example, you cannot perform data modeling or visualization before the ingestion stage. There is, however, the storage stage, which is a bit challenging to represent because it is required and is referenced from many other stages; so, where does it go in your process diagram? Again, you have the liberty of choosing that, but make sure to remember the first point as you make that decision. You do need to consider the fact that after each stage the data is most likely enriched or transformed, some of which you might want to illustrate and call out specifically in your process.
Finally, the third point is to determine which products and tools you will use to perform each stage of the Big Data pipeline. At this point you should have a good idea of available data analytics tools and what they can do. You should also know that some features overlap among the available products and features. As you design your process and define what happens within your chosen stages, locate a product that contains all the features necessary to fulfill the objectives of that stage. It makes sense to have as few products, libraries, operating systems, languages, and datastores as possible. Why? Because it’s easier that way. It is challenging, but not impossible to know Java, Scala, C#, and Python or Azure HDInsight, Azure Databricks, and Azure Synapse Analytics. But if you can specialize in a specific group of technologies, you have a greater chance of long‐term success.
Figure 5.1 shows one possible Big Data pipeline stage process.
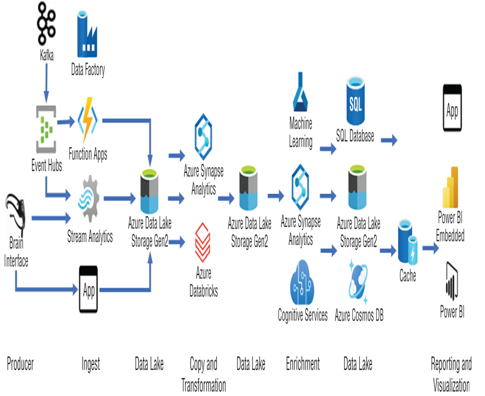
FIGURE 5.1 A Big Data pipeline process example
The illustration attempts to clarify the point that there is no single definition of what a Big Data pipeline process looks like. The design is completely up to your requirements; the sequence and products you choose are the key to a successful solution. As you proceed into the following sections, know that the transformation of your data can take place using numerous Azure products. It is up to you to decide which ones to use for your given circumstances.