Throughout the exercises in this book, you have created numerous notebooks. The notebooks are web‐based and consist of a series of ordered cells that can contain code. The code within these cells is what you use to ingest, transform, enrich, and store the data you are preparing for gathering insights. The notebooks are based on what was formally named IPython Notebook but is now referred to as Jupyter Notebook. The “py” in the name is intended to give recognition to its preceding name and the Python programming language. Behind the browser‐based shell exists a JSON document that contains schema information with a file extension of .ipynb. You will find support importing and exporting Jupyter notebooks in many places throughout the Azure platform. The following sections discuss many of them.
Azure Synapse Analytics
In Exercise 5.3 you created a notebook that targeted the PySpark language. When you hover over that notebook in Azure Synapse Analytics and click the ellipse (…), you will see the option to Export the Notebook. The supported formats are HTML (.html), Python (.py), LaTeX (.tex), and Notebook (.ipynb). The Jupyter notebook for Exercise 5.3 is in the Chapter05 directory on GitHub at https://github.com/benperk/ADE. There was a small change to the published Jupyter notebook versus the one you created in Exercise 5.3. The change was to break the code out from a single cell into three cells. Breaking the code into smaller snippets that are focused on a specific part of the ingestion, transformation, and storage is helpful because you can run each cell independently while testing.
Azure Databricks
You experienced the creation of numerous cells in Exercise 5.4, where you successfully transformed brainjammer brain wave data in Azure Databricks. The logic and approach you used in Exercise 5.4 was similar to what you did in Exercise 5.3. The target language for Exercise 5.4 was Scala, for learning purposes, but had there not been a difference, you could have imported the .ipynb file from Exercise 5.3 into Azure Databricks. As shown in Figure 5.14, you start by navigating towards adding a new resource in the workspace, which ultimately renders a pop‐up menu. The pop‐up menu contains the Import option.
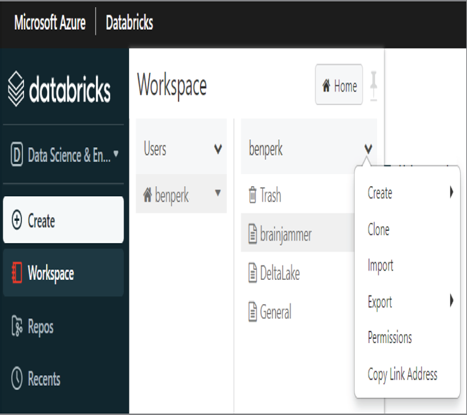
FIGURE 5.14 Jupyter notebooks—Azure Databricks Import option
Once the notebook is imported, you see the exact same code in the numerous cells as you created in Azure Synapse Analytics, as shown in Figure 5.15.
Some steps will be required to make the imported notebook run. For example, if the configuration that allows access to the storage has not been enabled on the Apache Spark cluster, then the notebook would fail to run.
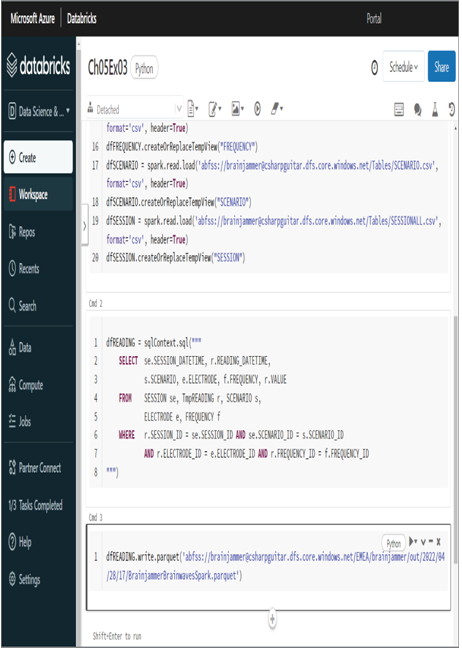
FIGURE 5.15 Jupyter notebooks—Azure Databricks imported