- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Databricks workspace you created in Exercise 3.14 ➢ click the Launch Workspace button in the middle of the Overview blade ➢ select the Compute menu item ➢ select the cluster you also created in Exercise 3.14 ➢ click the Start button ➢ select the + Create menu item ➢ select Notebook ➢ enter a name (I used brainjammer) ➢ select Scala from the Default Language drop‐down list box ➢ select the cluster you just started from the drop‐down list box ➢ and then click Create.
- Add the following configuration into the Advanced Options of the Apache Spark cluster:
fs.azure.account.key..blob.core.windows.net - Add the following Scala syntax code, which loads the Parquet brainjammer brain wave reading data ➢ and then run the code snippet in the cell:
- Add a new cell ➢ click the + that is rendered when hovering over the lower line of the default cell ➢ and then load the required reference data into DataFrames and temporary tables using the following syntax:
- Add a new cell, and then add the following Scala syntax, which transforms the raw brainjammer brain wave data:
- Add a new cell, and then save the result to a delta file using the following syntax:
The Azure Databricks workspace should resemble Figure 5.12.
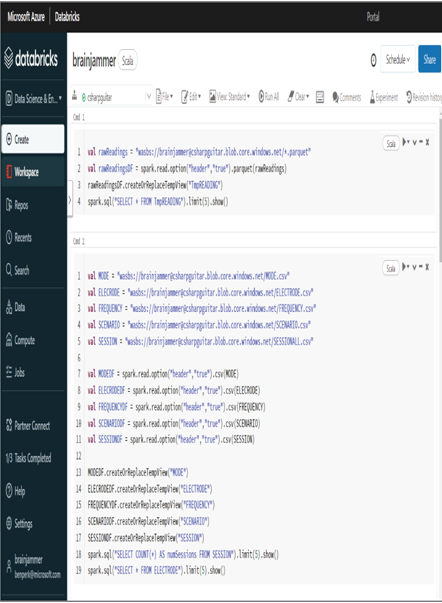
FIGURE 5.12 Transforming data using an Apache Spark Azure Databricks workspace
The first important point for Exercise 5.4 has to do with the location of the Parquet file that contains the raw reading data. The file in this exercise is hosted in a blob container and in a different Azure storage account from the one that contains your ADLS container. You might overlook that aspect of this exercise and get stuck. You can see this in the value of the Spark configuration setting in step 2. Notice that it contains blob.core.windows.net and not the dfs.core.windows.net endpoint address that exists for ADLS containers.
fs.azure.account.key..blob.core.windows.net
To make sure this is clear, Figure 5.13 illustrates this transformation configuration. A notebook named brainjammer is running on an Apache Spark cluster in Azure Databricks. The Scala code within the notebook retrieves a Parquet file from an Azure blob storage container using the wasbs protocol. The data in the file is transformed and then saved into a Delta Lake.

FIGURE 5.13 Transforming data using Apache Spark Azure Databricks configuration
Note that it is possible to make a connection to an ADLS container from an Azure Databricks Apache Spark cluster. Doing so requires Azure Key Vault (AKV) and MI, which have not been covered yet. You will do another exercise with this in Chapter 8, “Keeping Data Safe and Secure,” where security is discussed. However, this approach is sufficient for learning how things work, until your project gets large enough to need a larger team that requires a greater level of control, privacy, and security policies.
Exercise 5.4 begins with the creation of a notebook, which is downloadable from the Chapter05/Ch05Ex04 GitHub directory. There is a Scala file and an HTML file for your reference and to import onto the Apache Spark cluster, if desired. The first code snippet sets the path to the Parquet file; in this case, it’s a wildcard setting, since there is only a single file in the container ending with .parquet. If more files with that extension existed in the container, a more precise path would be required. The file is loaded into the variable named rawReadingsDF and then used as the data source for the TmpREADING temporary view. The last line retrieves a few rows from the table, just to make sure it resembles what is expected.
val rawReadings = “wasbs://@.blob.core.windows.net/*.parquet”
val rawReadingsDF = spark.read.option(“header”,”true”).parquet(rawReadings)
rawReadingsDF.createOrReplaceTempView(“TmpREADING”)
spark.sql(“SELECT * FROM TmpREADING”).limit(5).show()
The next notebook cell that included the Scala code loaded the path to all necessary reference data. The path was then used to load CSV files from a blob storage container and to use them to populate reference table data. A few SELECT queries on those tables made sure everything loaded as expected. The next cell in the notebook is where the transformation happens, using the spark.sql() method and passing it a query that joins together the reading and reference data resulting in output in a more usable form. That output is rendered to the output window for proofing purposes.