- Enter the following PySpark SQL syntax to transform the data into the preferred format:
- Write the results to your ADLS data lake using the following snippet as an example. Note that there should be no line break in the path; it is broken for readability only.
- Consider renaming the notebook (for example, Ch05Ex03) ➢ click the Commit button ➢ click the Publish button ➢ select the Integrate Hub ➢ open the pipeline you created in step 3 (IngestTransformBrainwaveReadingsSpark) ➢ drag and drop a notebook from the Synapse group in the Activities pane onto the canvas ➢ provide a name (I used TranformReadingsParquet) ➢ on the Settings tab select the notebook you just created (Ch05Ex03) ➢ select your Spark pool ➢ click the square on the middle‐right edge of the Data flow activity ➢ and then drag and drop it onto the Notebook activity. Figure 5.10 illustrates the pipeline configuration.
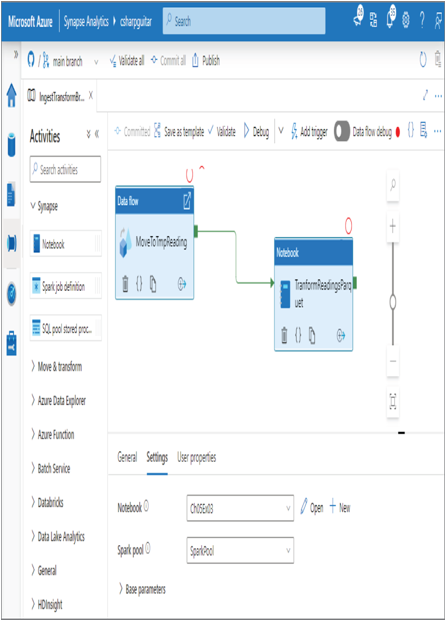
FIGURE 5.10 Transforming data using an Apache Spark Azure Synapse Spark pool
- Click the Commit button ➢ click the Publish button ➢ select the Add Trigger menu option ➢ and then select Trigger Now. Once complete the publishing view the Parquet files in your ADLS data lake.
That was a long and complicated exercise, so congratulations if you got it all going. Figure 5.11 illustrates how what you just did all links together. After reviewing it, read on to further understand those steps, the features, and the code added to the notebook.
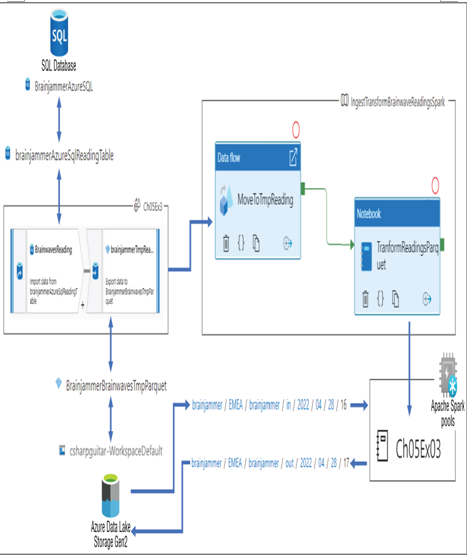
FIGURE 5.11 Transforming data using Apache Spark Azure Synapse Analytics
Exercise 5.3 begins with the creation of a data flow that performs two actions. The first action is to retrieve the data from a table named [dbo].[READING] that resides on an Azure SQL database. This import requires a dataset to hold the data and to apply its schema. That dataset then has a dependency on the linked service, which provides connection details and the required data contained within it. In Figure 5.11 you see an action named BrainwavesReading, which relies on a dataset named brainjammerAzureSqlReadingTable, which uses the BrainjammerAzure SQL linked service to connect to the Azure SQL database. The next data flow action is configured to ingest the data stream from Azure SQL and write it to an ADLS container in Parquet format. This data flow is added as an activity in an Azure Synapse Pipeline, which contains the data flow and a notebook named Ch05Ex03.
The notebook PySpark code begins by retrieving the Parquet file from the ADLS container and storing it into a DataFrame. The data loaded into the DataFrame is then stored on a temporary table using the registerTempTable() method, as follows:
df = spark.read .load(‘abfss://@.dfs.core.windows.net/../in/2022/04/28/16/*.parquet’, format=’parquet’)df.registerTempTable(“TmpREADING”)
Reference tables are required to transform the data on the TmpReading table and are loaded into a DataFrame and then stored into temporary tables. The CSV files need to be uploaded to your ADLS container prior to successfully running that code.
The next step is to perform a query that transforms the data on the TmpReading table into the format that has been assumed to be most optimal for querying and insight gathering.
The data ends up being in a format like the following:
Total brainwave readings: 4539221
Use df.distinct().count() and df.show(10) to render the total number of rows in the DataFrame and a summary of what the data looks like, respectively. These files are available in the BrainwaveData/Tables directory at https://github.com/benperk/ADE.
Azure Databricks
If you already have a large solution that utilizes Databricks and want to outsource the management of the platform to Azure, you can migrate your solution to Azure. Azure Databricks is the product offering to individuals and corporations that want to run their Big Data analytics on the Azure platform. Complete Exercise 5.4, where you will transform data using Azure Databricks. It is assumed that you have completed the previous exercises and have the Parquet file that is an extract of the [dbo].[Reading] table existing on the Azure SQL database. If you did not perform Exercise 5.3, you can download the Parquet file from the BrainwaveData/dbo.Reading directory at https://github.com/benperk/ADE. The file is approximately 43 MB.