Transform Data Using Azure Data Factory
The capabilities for achieving most activities in Azure Data Factory (ADF) are also available in Azure Synapse Analytics. Unless you have a need or requirement to use ADF, you should use the go‐forward tool Azure Synapse Analytics instead. In any case, the current DP‐203 exam has a requirement for this scenario. Therefore, perform Exercise 5.2, where you will extract data from an Azure Synapse Analytics SQL pool and transform the data structure into CSV and Parquet files.
EXERCISE 5.2 Transform Data Using Azure Data Factory
- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Data Factory Studio you created in Exercise 3.10 ➢ on the Overview blade, click the Open link in the Open Azure Data Factory Studio tile ➢ select the Manage hub ➢ select the Linked Services menu item ➢ select the + New link ➢ create a linked service (in my example, BrainjammerAzureSynapse) for your Azure Synapse Analytics dedicated SQL pool (make sure it is running) ➢ and then, if required, review Exercise 3.11, where you created a linked service in ADF. The configuration should resemble Figure 5.6.
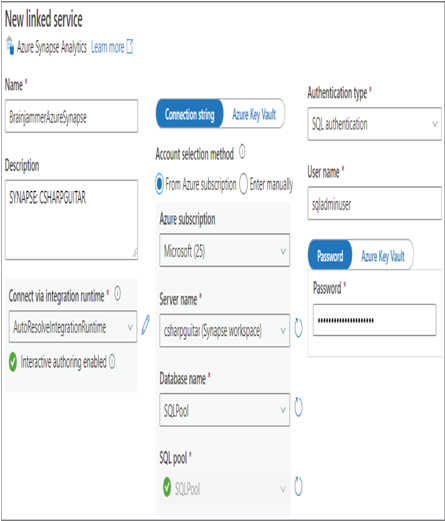
FIGURE 5.6 Azure Data Factory Synapse—linked service
- Create another linked service (for example, BrainjammerADLS) to the Azure storage account that contains the ADLS container you created in Exercise 3.1.
- Select the Author hub ➢ create a new ADLS dataset to store the Parquet files (for example, BrainjammerParquet) ➢ use the just created linked service (for example, BrainjammerADLS) ➢ select a path to store the files (for example, EMEA\brainjammer\in\2022\04\26\17) ➢ click OK ➢ enter a file name (I used BrainjammerBrainwaves.parquet) ➢ and then create a new Azure Synapse dataset that retrieves data from the [brainwaves].[FactREADING] table (for example, BrainjammerAzureSynapse). The configuration should resemble Figure 5.7.
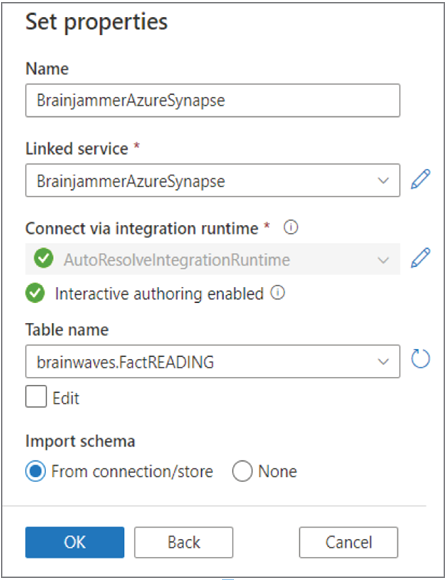
FIGURE 5.7 Azure Data Factory—Synapse dataset
- Create a new ADLS dataset to store the CSV files (for example, BrainjammerCsv) ➢ use the same linked service as you did for the Parquet file (for example, BrainjammerADLS) ➢ place into a directory (for example, EMEA\brainjammer\in\2022\04\26\17) ➢ click OK ➢ enter a file name (I used BrainjammerBrainwaves.csv) ➢ and then click Save.
- Create a new pipeline ➢ from Move & Transform add two Copy Data activities ➢ name one ConvertToParquet ➢ select BrainjammerAzureSynapse as the source dataset on the Source tab ➢ select BrainjammerParquet as the sink dataset ➢ name the other activity ConvertToCsv ➢ click Save ➢ select BrainjammerAzureSynapse from the Source Dataset drop‐down on the Source tab ➢ and then select BrainjammerCsv from the Sink Dataset drop‐down on the Sink tab.
- Click the green box on the right side of the ConvertToParquet activity, and then drag and drop the activity onto the ConvertToCsv activity. The configuration should resemble Figure 5.8.
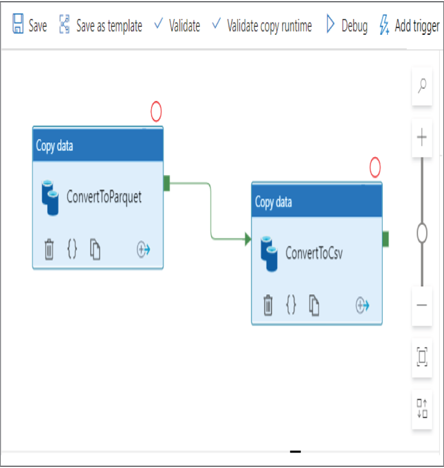
FIGURE 5.8 Azure Data Factory—Synapse pipeline
- Click the Save All button to store your changes on the linked GitHub repository ➢ click the Publish button ➢ click the Add Trigger button ➢ select Trigger Now ➢ select the Monitor hub ➢ select Pipeline Runs to view the status ➢ view the files in the ADLS container directory ➢ and then stop the dedicated SQL pool.
Figure 5.9 shows a more elaborate illustration of what you just implemented. You created a linked service to an Azure Synapse SQL pool, which is used by a dataset as the source of the data to be transformed. The data retrieval exists in the [brainwaves].[FactREADING]table on the dedicated SQL pool. You also created two datasets for output sinks: one in the Parquet format and another in CSV‐delimited text. Those two datasets use the linked service bound to your ADLS container.
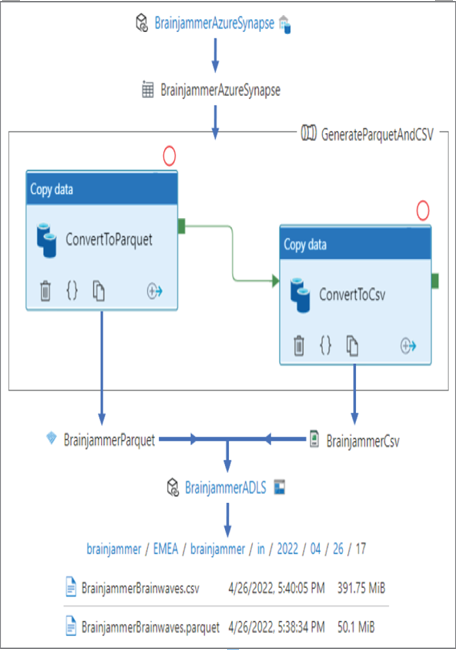
FIGURE 5.9 Azure Data Factory Synapse—pipeline transformation
The ADLS container contains a directory that is useful in terms of storing data logically, in that you can conclude information from the names of the file and folders. This logical structure helps with archiving unnecessary data and data content discovery. To execute the transformation, you created a pipeline that contained two activities. The first activity pulls data from the source, performs the transformation, and places it into the sink in the configured Parquet format. The second activity performs the same but formats the output into CSV format. Saving, publishing, and triggering the pipeline results in the files being written to the expected location in your ADLS container data lake. You might notice that the resulting files are large, which could be because there are more than 4.5 million rows in the [brainwaves].[FactREADING] table, which are extracted and stored into the files. There is quite a difference between the size of Parquet and CSV files, even though they both contain the same data. Remember that a dedicated SQL pool runs most optimally when file sizes are between 100 MB and 10 GB; therefore, in this case the size is in the zone. However, it is recommended to use Parquet versus CSV in all possible cases. Processing files on a Spark pool has an optimal file range between 256 MB and 100 GB, so from a CSV perspective it is good. But from the recommended Parquet file format perspective, the data is on the small side, even with 4.5 million rows.