It does provide some benefit to understand the structure of the data you must ingest, transform, and progress through the other Big Data pipeline stages. It is helpful to know because as you make decisions or conclusions about why data is stored in a certain way or what a column value is, knowing how the data was formed gives you a basis for coming to your conclusion. The data used in many examples up to now has been brain waves, which were captured from a BCI manufactured by SDK and stored as both JSON and CSV files on a local workstation. You can find the code that captured and stored that data on GitHub at https://github.com/benperk/ADE, in the Chapter02/Source Code directory, in a file named BrainReadingToJSON.cs. The JSON‐formatted brainjammer brain waves were then uploaded into an Azure SQL database, like the one you created in Exercise 2.1. The code that performed that action is located in the same location as the previous source code file but is named JSONToAzureSQL.cs. The result of the storage in Azure SQL resulted in a relational data structure like the one shown in Figure 2.2.
The brain wave readings were ingested in Chapter 4, “The Storage of Data,” specifically in Exercise 4.13. For reference, Figure 5.2 illustrates that ingestion. Note that although the data existed in a relational Azure SQL database, the data source could have existed in any location and in any format. The objective of ingestion in this scenario was to retrieve it from its current location and pull it into Synapse Analytics and the data lake for transformation. As you may recall, no transformation of the data took place in this set of pipeline activities.
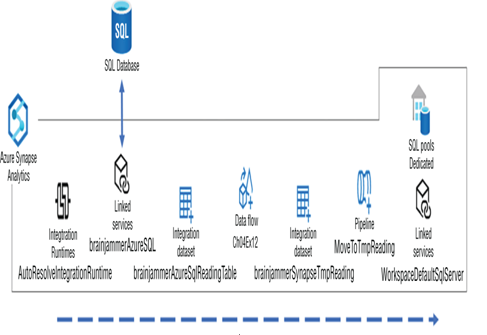
FIGURE 5.2 Azure Synapse Analytics—ingesting Brainjammer brain waves
This activity could have also been considered preparing the data for transformation, i.e., a prepare or preparation stage. The term ingestion often implies a streaming scenario. In a streaming scenario the data is being ingested continuously in real time, in contrast to this scenario, where data already exists in some external datastore and gets pulled, pushed, moved, or copied into a data lake on the Azure platform. Again, it depends on how you define your process.
The way the data is initially captured and stored has a lot to do with the complexity and effort required to transform it. But you also need to know how the data should look after the transformation, which is sometimes difficult to define at the early stages. When you are doing a transformation on a dataset for the first time, you should expect to need numerous iterations and progress through numerous versions of your transformation logic. The final data structure needs to be in a state where business insights can be learned from it. Consider the way the brainjammer brain waves were stored on the Azure SQL database.
They were stored in a classic data relational model, with primary and foreign keys between numerous reference tables. And after much thought, the final data format, which at the time seems to give the best chance of learning from it, is what you will see and implement in Exercise 5.1. The transformation is only a single SQL query and CTAS statement, so it is not an extensive transformation. However, you will certainly come across some very complicated scenarios. Those scenarios are the reason for the many schema modifiers (refer to Table 4.4) and data flow transformation features (refer to Table 4.5) available for managing and performing such transformations. After this initial transformation, when some exploratory analysis takes place, you might uncover some new angle to approach and transform the data, to get even more benefit from it. For starters, complete the Exercise 5.1.